Kubernetes Fundamentals:
Open source platform for running cloud native apps
--------Cloud native apps------ containers
--------Kubernetes------------- platform- linux nodes, vm, cloud instance
--------Infrastructure--------- IAAS
Kubernetes
1. Control Plane (Brain)
- is a api server, schedular, controllers, persistence store
- Store - etcd (stateful)
- api server (kubectl -> requests(POST)-> API)(YAML)
2. Workers Nodes (running applications)
Kubernetes API:
RESTful CRUD: Create, read, update, delete
kubectl command is used for making API requests
kubectl -> YAML -> Kubernetes Cluster (Desired State -> Current State)
API groups:
- Core API
- apps API
- authorization API
- storage API
(SIGS look after API development)
Kubernetes Objects:
Pod
- contains one or more containers
- atomic unit of scheduling
- object on the cluster
- Defined in the v1 API groups
Deploy
- Object in the cluster
- defined in the apps/v1 api groups
- Scaling
- Rolling updates
Daemon set:
- one pod per node
Sts (stateful sets):
- stateful app components
App Architecture:


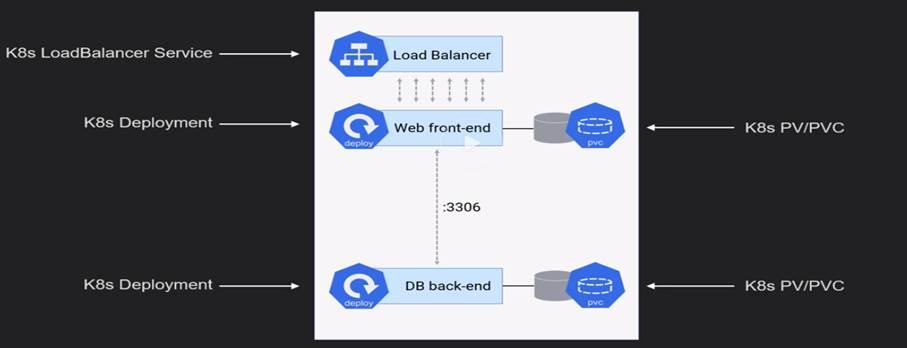

K8s Networking:
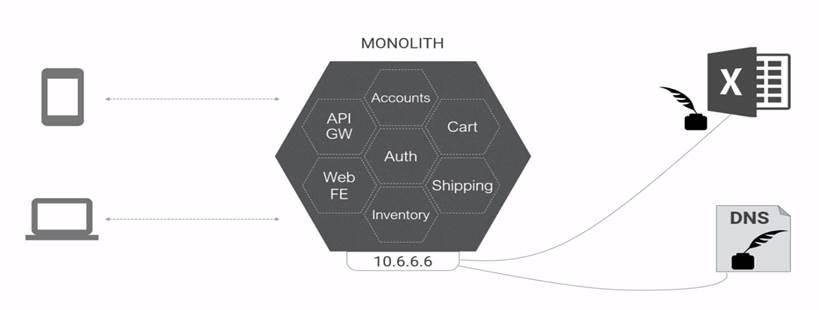
Old world:
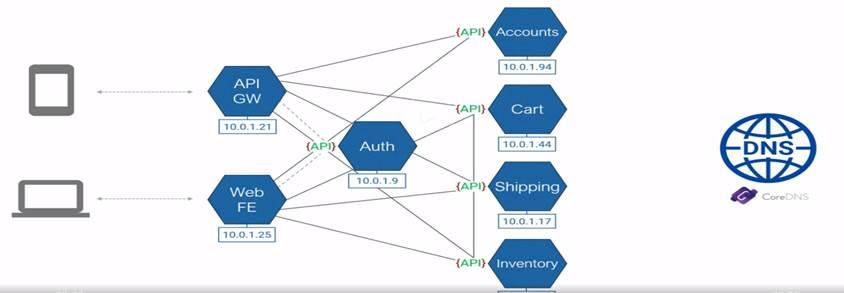
New World:

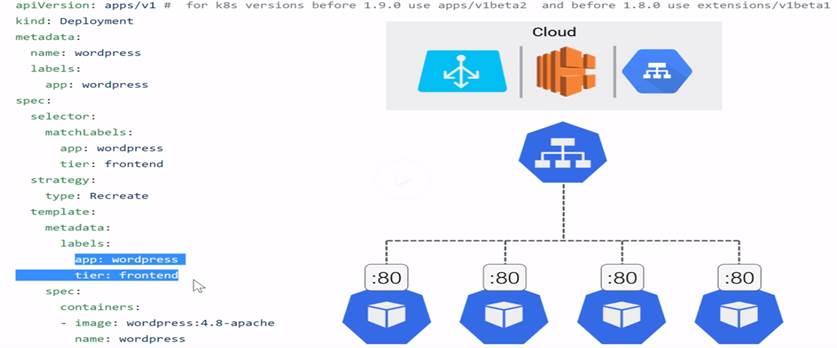
K8s deployed on IAAS launches IAAS specific loadbalancers when we request service of type loadbalancer in K8’s.

Kubernetes Networking:
Rules:
- All nodes in a cluster can talk to each other
- All Pods on the network can talk to each other w/o NAT
- Every Pod gets its own IP address

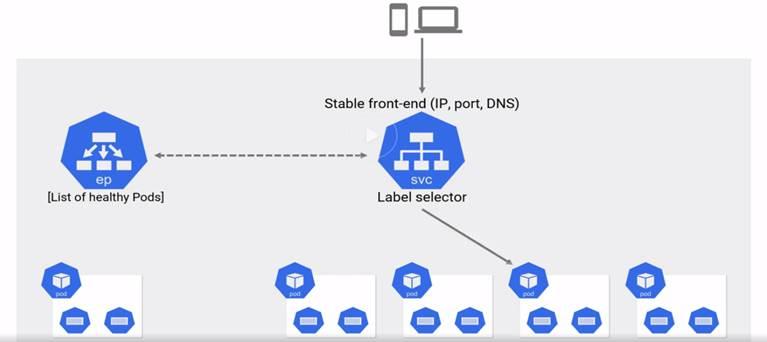
Kubernetes Services:
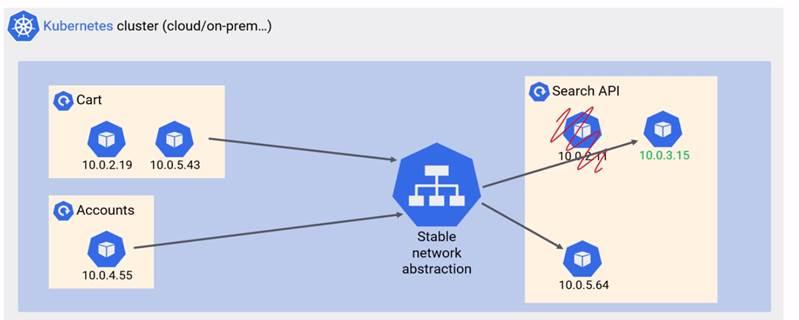
Service name and ip address are stable do not change are registered with native DNS service of cluster.

Service and Pods are connected via label selector defined for service.
Whenever service object is created K8s creates another object called endpoint object which tracks the pods coming alive of shutting down based on the label selector.
Endpoint object is the list of ips for the pods alive.
Service object is always watching the API server for new pods using the label selector and updates the end-point object with the ips.
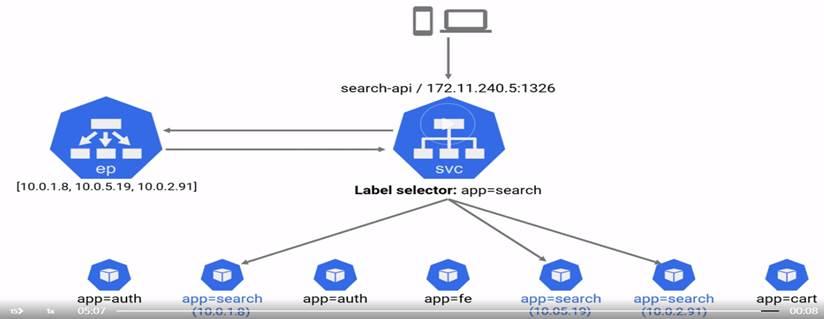
3 major types of services:
- LoadBalancer
- NodePort
- ClusterIp


Node Ip address and node port – can get you access to the pods in specific node in the cluster
AWS and Azure uses NodePort Port behind the load balancer to connect to K8S cluster.


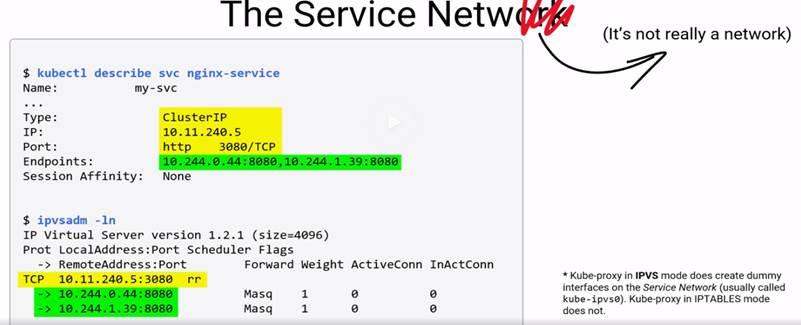
Service Networks:
3 Networks:
- Node Network
- Pod Network
- Service Network (Its not even in the K8 networks i.e. Node and Pod networks)
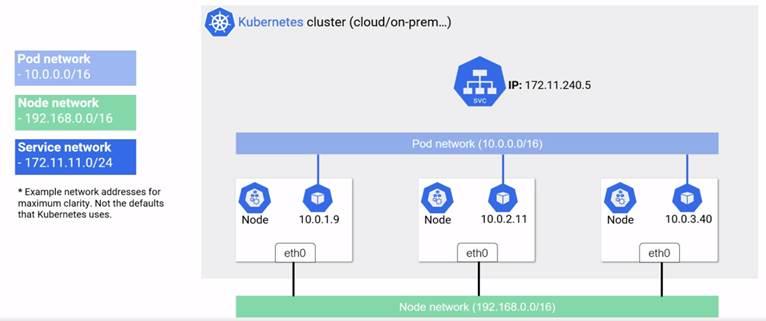
Every Node has 3 components i.e. container runtime, kubelet and k-proxy. Node is basically a VM or physical machine on K8s network.

Kubernetes architecture with cloud controller manager.
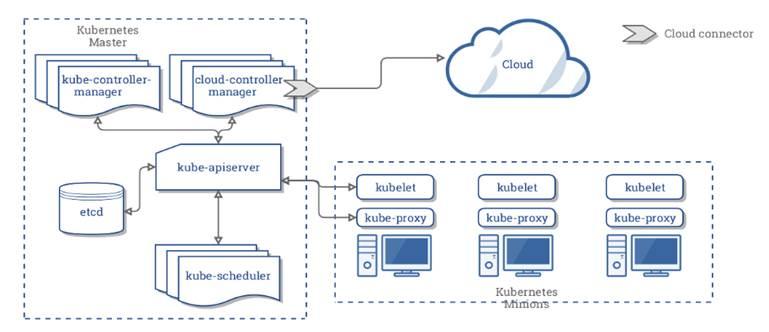
Kube proxy : it writes the IPVS/IPTables rules on each nodes, any request addressed to service network, rewrite the headers, and send them to the appropriate pods in the pod network.

Flow will look like below:

Kube-proxy IPVS mode is preferred and scalable


All containers in the Pod share the same Pod’s network stack and can talk via localhost.

Storage in Kubernetes:


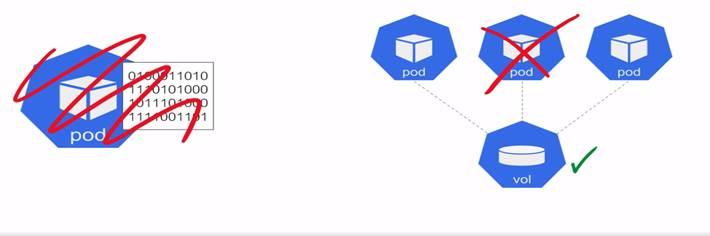
In Kubernetes Storage is First Class Citizen.

K8s has Persistent Volumes Subsystem for consumption which uses Container Storage Interface as connector to Real Storage system.
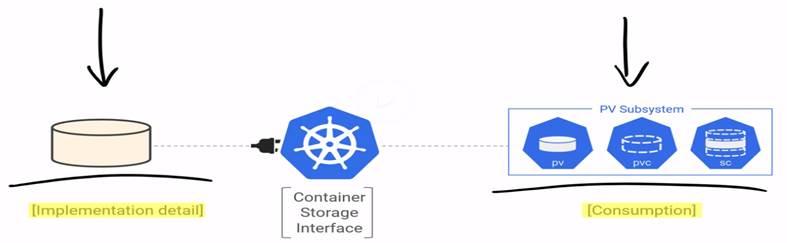
PV are storage resource i.e. 20 GB fast SSD
PVC are ticket to use PV.
SC are ways to implement PV and PVC in a dynamic way.

Container Storage Interface:
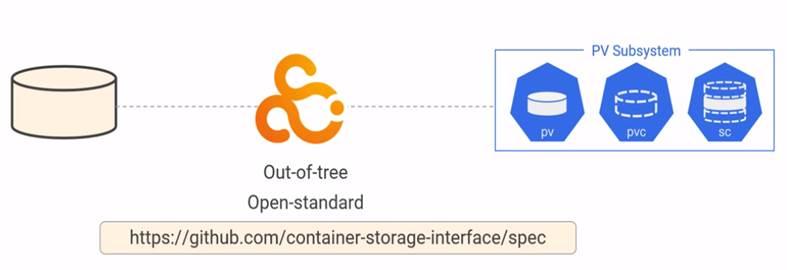
PV Subsystem:


PV’s are created on the cluster but it exists on external system or cloud as shown above for google platform.
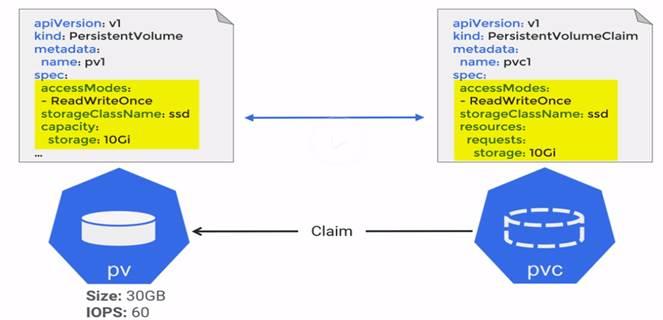
To access PV’s, one needs PVC i.e. claim ticket. Which is defined like below in YAML file.
Sample PV YAML:
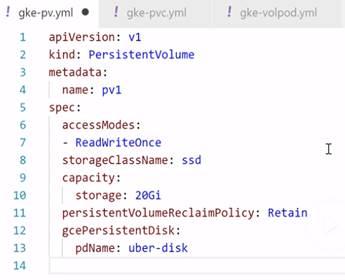
Note: pdName called uber-disk is a volume present on your cloud platform/ on premises, outside of the cluster.
PV access modes:

A PV can have only one active claim i.e. PVC at the moment.
RWO – only one Pod can RW
PWM – multiple pods can RW
ROM – multiple pods can RO
Only File based volumes support RWM. Block volumes do not support RWM.
Retain Policy can be delete or retain.
PVC YAML:
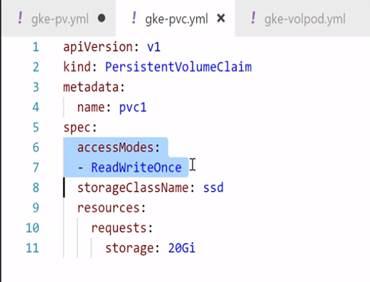
PV and PVC spec has to match.
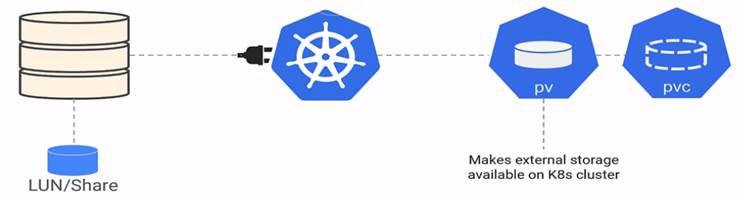
Pod using PV and PVC:

Dynamic provisioning with Storage Classes: It enable dynamic provisioning of volumes.

PV Sub system control loop checks for PVC created for the storage class and creates the associated PV.
Code to Kubernetes:

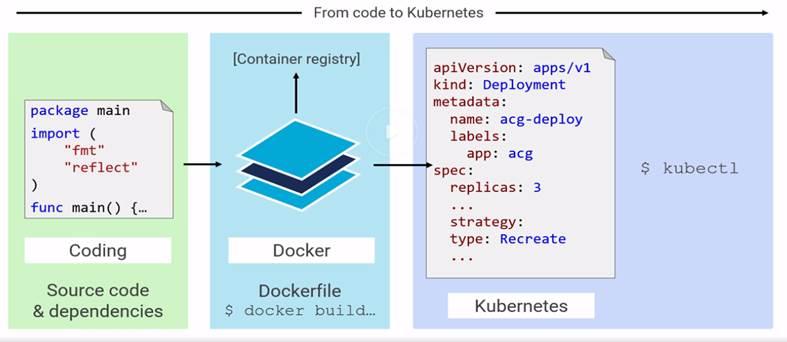
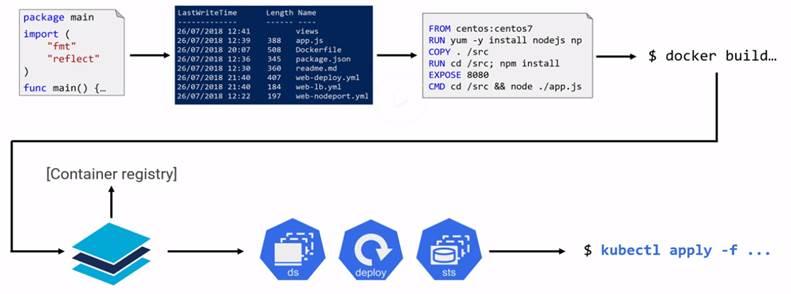
Kubernetes Deployments:
Deployment manages a single Pod i.e. one deployment can run only one type of Pod.
Deployment in K8 are completely declarative. We should never change that.

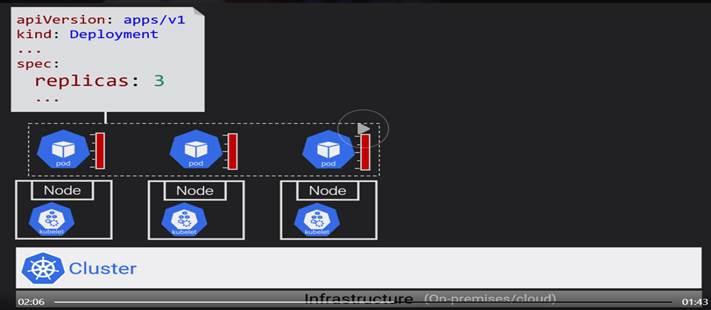
Replica set creates 3 identical Pods for the specs defined.

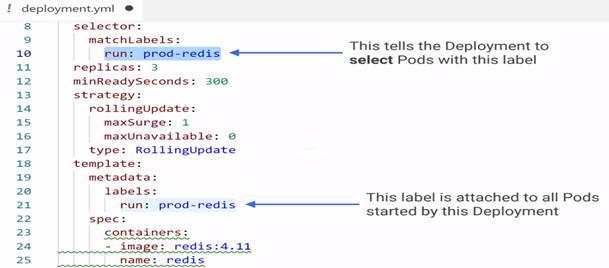
Strategy defines how to update live app in K8s. K8 creates another replica set and keep on surging the Pods in new replica set and removing from old replica set until the process is over.
Minreadyseconds define the amount of seconds K8 has to wait before K8 launches next rolling updates.

Labels are most important in K8s.

Auto Scaling in K8s:
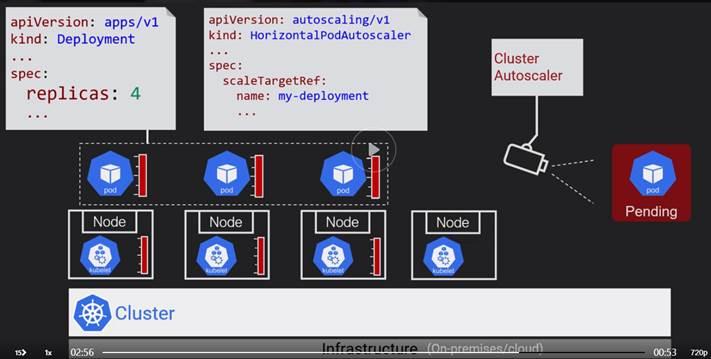
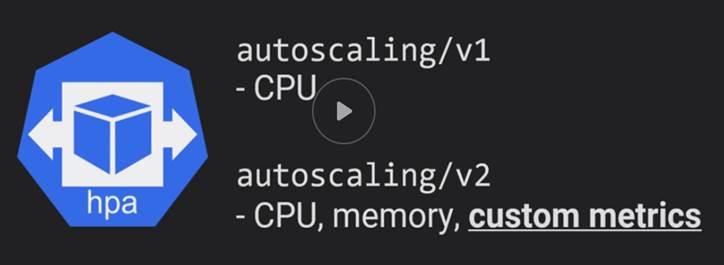
Horizontal Pod Autoscaler: to add more Pods
Cluster Autoscaler: to add more nodes
If Pods CPU and memory is full:
Horizontal Auto Scaler will start scaling by adding more Pods.

If cluster memory is also full then Pods scaling will add the Pod deployment in the pending state.

Once pods start going into Pending state, Cluster Autoscaler will kickin and adds more nodes to the cluster and Pending Pods will be deployed.
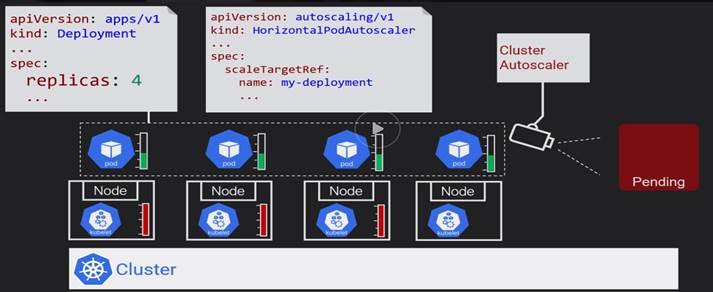


Cluster autoscaler triggers every 10 seconds. Cluster auto scalers scales based on standard requests. Horizational autoscaler scales on actual values.
Pods should always make resource requests for scaling to work. Cluster scaling works based on what is getting requested.

RBAC and Admission Control:
Client: kubectl and K8 control pane components
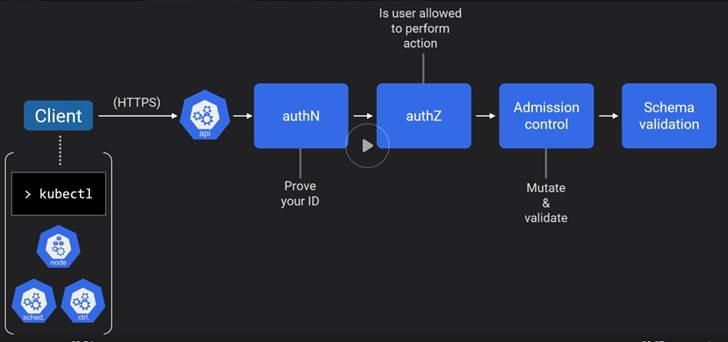
RBAC is enabled since 1.6

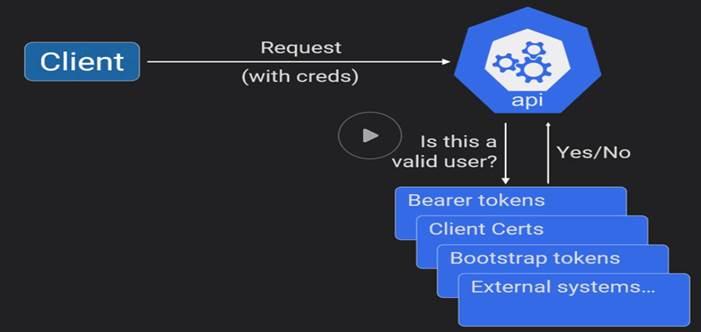
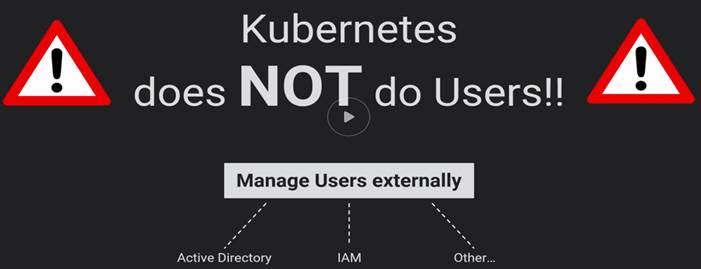

Authorization mode: Node, RBAC.
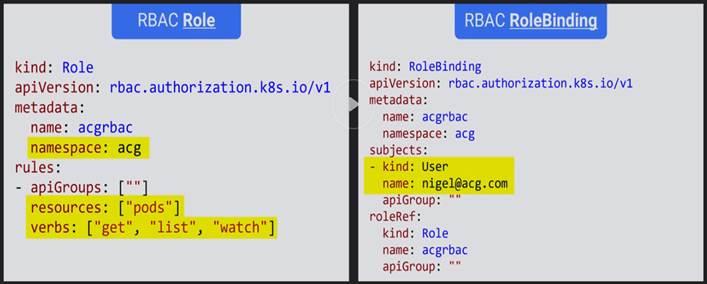
We can use kubectl to add RBAC role and role bindings.
Admission control is policy enforcements and can be externalized using webhooks.

Admission control has two steps i.e. mutating and validating. Mutating modifies the request. And both steps should return true. Otherwise request will stop.


Other Kubernetes stuff:

Comments
Post a Comment